분류용 데이터 세트 준비
분류 문제를 위하여 데이터 세트를 준비해 보겠다. 데이터 세트는 사이킷런에 포함된 '위스콘신 유방암 데이터 세트(Wisconsin breast cancer dataset)'를 사용한다.
유방암 데이터 세트
유방암 데이터 세트에는 유방암 세포의 특징 10개에 대하여 평균, 표준 오차, 최대 이상치가 기록되어 있다. 여기서 해결할 문제는 유방암 데이터 샘플이 악성 종양(True)인지 혹은 정상 종양(False)인지를 구분하는 이진 분류 문제이다.
의학 분야에서는 건강한 종양을 양성 종양이라고 부르고 건강하지 않은 종양을 악성 종양이라고 부른다는 것을 주의해야 한다. 지금은 해결 과제가 악성 종양이므로 양성 샘플이 악성 종양인 셈이다. 정리하면 아래와 같다. 앞에서 부터 의학, 이진 분류이다.
- 좋음 : 양성 종양(정상 종양), 음성 샘플
- 나쁨 : 악성 종양, 양성 샘플
유방암 데이터 세트 준비
유방암 데이터 세트를 불러오려면 사이킷런의 datasets 모듈 아래에 있는 load_breast_cancer() 함수를 사용하면 된다.

객체를 만들어 cancer에 저장했으므로 cancer이 data와 target을 살펴보겠다. 먼저 입력 데이터인 data의 크기를 알아보겠다.

cancer에는 569개의 샘플과 30개의 특성이 있다는 것을 알 수 있다. 이 중에 처음 3개의 샘플을 출력해 보겠다.

특성 데이터를 살펴보면 양수의 실수 범위의 값으로 이루어져 있음을 알 수 있다. 특성이 30개나 되니 산점도로 그려서 표현하기 어렵다. 그래서 이번에는 산점도 대신 박스 플롯(box plot)을 이용하여 각 특성의 사분위(quartile) 값을 나타내 보겠다.
박스 플롯은 1사분위와 3사분위 값으로 상자를 그린 다음 그 안에 2사분위(중간값) 값을 표시한다. 그런 다음 1사분위와 3사분위 사이 거리(interquartile range)의 1.5배만큼 위아래 거리에서 각각 가장 큰 값과 가장 작은 값까지 수염을 그린다.

다음으로 데이터 세트를 이용하여 박스 플롯을 그려보겠다.

박스 플롯을 보면 4, 14, 24번째 특성이 다른 특성보다 값의 분포가 훨씬 크다는 것을 알 수 있다. 다른 특성과 차이가 나는 특성들을 확인해 보겠다. 4, 14, 24번째 특성의 인덱스를 리스트로 묶어 전달하면 각 인덱스의 특성을 확인할 수 있다.
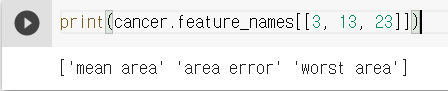
결과를 보니 모두 넓이와 관련된 특성이다.
우리가 해결할 문제는 '음성 샘플(정상 종양'과 '양성 샘플(악성 종양)'을 구분하는 이진 분류 문제이기 때문에 cancer.target 배열 안에는 0과 1만 들어 있다. 여기서 0은 음성 클래스, 1은 양성 클래스를 의미한다. 다음은 넘파이의 unique() 함수를 사용하여 타깃 데이터를 확인한 것이다. 이때 return_counts 매개변수를 True로 지정하면 고유한 값이 등장하는 횟수까지 세어 반환한다.

unique() 함수가 반환한 값을 확인해 보니 두 덩어리의 값을 반환하고 있다. 왼쪽의 값은 cancer.target에 들어 있는 고유한 값(0, 1)을 의미한다. 즉, cancer.target에는 0이나 1이라는 값만 들어 있다. 오른쪽의 값은 타깃 데이터의 고유한 값의 개수를 센 다음 반환한 것이다. 즉, 위의 타깃 데이터에는 212개의 음성 클래스(정상 종양)와 357개의 양성 클래스(악성 종양)가 들어 있다.
마지막으로 예제 데이터 세트를 x, y변수에 저장하겠다.
